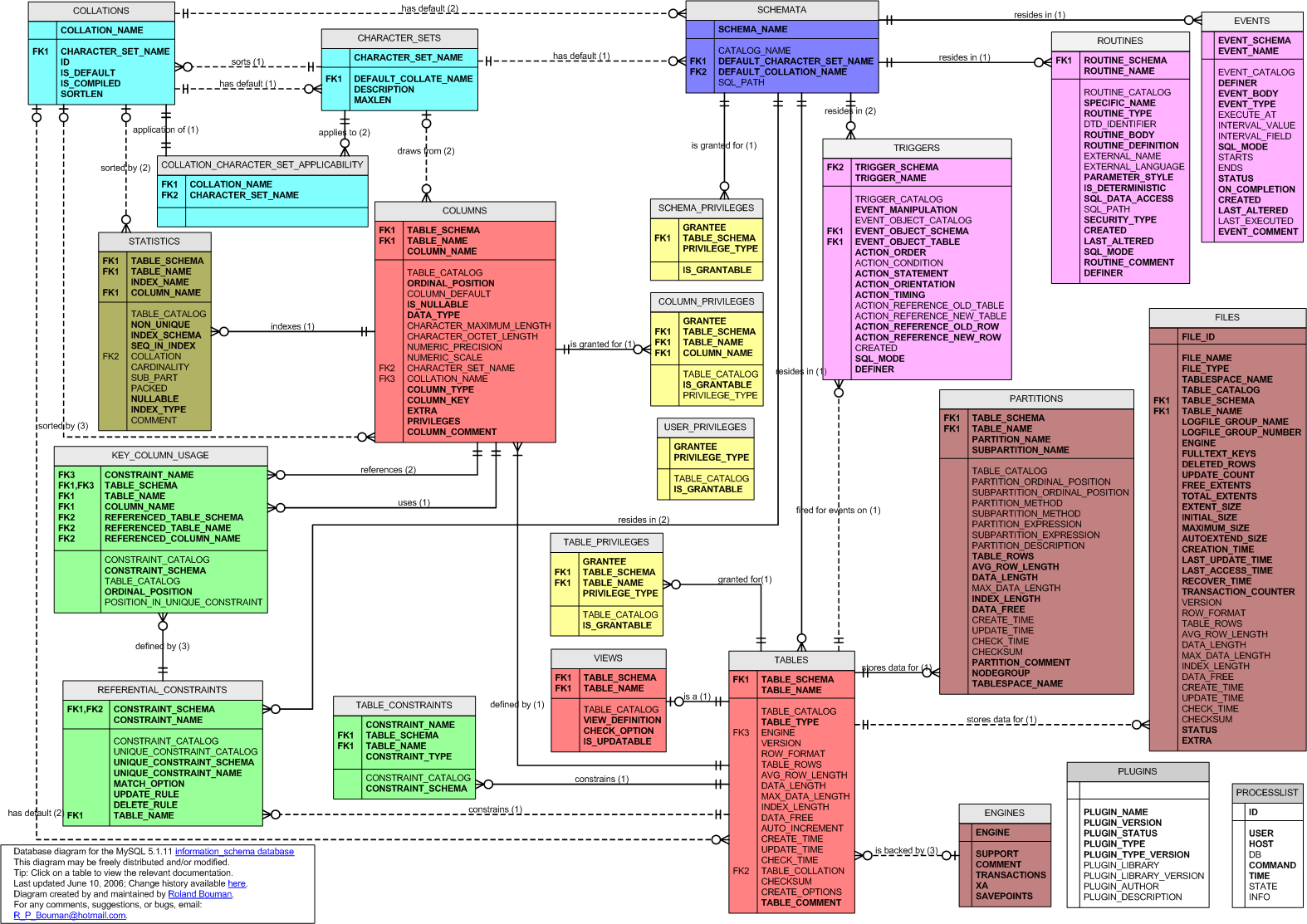
This page contains a clickable diagram of the MySQL 5.1 data dictionary implementation, the information schema database. You can click on a table to link through to the relevant MySQL reference page. I hope you'll find it worthwhile:
This is a copy of the diagram by Roland Bouman, whose website went offline in Match 2012. The diagram was initially created in Microsoft Visio by reverse-engineering the information_schema database via the MyODBC driver. Afterwards, relationships were added by hand. If you notice any mistakes, or omissions, or if you have a question, just send me an email at my hotmail adres (R_P_Bouman at hotmail dot com) [no support anymore].
You should realise that this is not a physical data model of the implementation. Rather, it is a conceptual model of the structure of the information schema database As such, it can be used as a guide when building queries against the information schema.
You can download the original Visio 2002 file here. You'll probably need the Entity Relationship stencil shipped with your Visio product. The diagram is also available as a gif image.
You are free to copy or redistribute the diagram in any form. This includes saving and redistributing the diagram in another format (pdf, jpeg, whatever). However, I would appreciate it if you would not modify the contents of the model without notifying me. Also, I would appreciate it if you do not remove the footer identifying me as the author of the diagram.
The diagram is based on the Visio stencil for Entity Relationship modelling. Entities (Tables) are drawn as rectangles, relationships are drawn as lines connecting entities. Cardinalities are drawn using the usual "crowfeet" markers.
Some general notes on the notation provided by Visio:
I used background colors to mark functionally related tables. Depending upon your criteria, you could recognize other functionally related units. I chose these colors:
Relationships all have a rolename. Right after the rolename, you can see an integer between left and right parenthesis. The integer between the parenthesis corresponds to the foreign key markers (FK1, FK2, etcetera) appearing right before some column names. To see how this works, look at the relationship between SCHEMATA and TABLES. The rolename is "resides in", and it is followed by a "(1)". The "1" between the parenthesis corresponds to the TABLES column TABLE_SCHEMA. Right before that columns you can see the "FK1" marker, where the "1" in "FK1" indicates correspondence to the "1" between the relationship parenthesis.
To avoid cluttering of the diagram, only one rolename is displayed. I chose to display the rolename that applies to the child end (usually the "many" side) of the relationship. (Visio refers to this as the "Inverse Text" of the "Verb phrase".) This type of rolename expresses how the child entity relates to the parent entity. In most cases, only one such rolename is enough to think of a meaningful phrase for the other rolename. My choice for naming the child end instead of the parent end is arbitrary. I am willing to change this if you provide suggestions to do so.
Using the entity names and the rolename, the semantics of a relationship can be expressed in a simple english sentence:
By this convention, the relationship between TABLES and SCHEMATA would read:
For a more detailed understanding of the relationship, expand this pattern by specifying the cardinalities.
Cardinalities specify in what quantities instances at either side of a relationship relate to each other.
Sticking to our previous example, the sentence would read:
A Table resides in exactly one schema.
Another example, for the relationship between COLUMNS and CHARACTER_SETS:
A Column optionally draws (characters) from at most one Characterset.
I tried to choose the rolenames as descriptive as possible, but any suggestions are very welcome.
In MySQL, indexes as well as constraints reside in same schema as the table on which they are defined. The same holds for triggers: a trigger always resides in the same schema as that of it's associated table. There's a difference too: indexes and constraints are uniquely identified by their respective name (INDEX_NAME and CONSTRAINT_NAME) within their associated table. Triggers are uniquely identified by their name within their schema (which is always the same schema as that of their associated table).
This affects the diagram as far as the columns CONSTRAINT_SCHEMA (tables: TABLE_CONSTRAINTS and KEY_COLUMN_USAGE) and INDEX_SCHEMA (table: STATISTICS) are concerned. Because we know that the value for these columns is identical to the value in the TABLE_SCHEMA column, we can get away with not including these columns in the identifiers of their tables. Instead, we can use the TABLE_SCHEMA column. Also, there's no need to include separate relationships between SCHEMATA and TABLE_CONSTRAINTS and SCHEMATA and STATISTICS. The former is already determined because relationships exist between SCHEMATA and TABLES and TABLES and TABLE_CONSTRAINTS. The latter is already determined because relationships exist between SCHEMATA and TABLES, TABLES and COLUMNS, and finally, COLUMNS and STATISTICS.
So, triggers are in a separate namespace: triggers can be uniquely identified within a schema by using their name (TRIGGER_NAME). Although a trigger is always associated to a table much in the same way as a table constraint or a index is, the triggers table does have it's 'own' identifier, which is made up of TRIGGER_SCHEMA and TRIGGER_NAME, although the value of the TRIGGER_SCHEMA and EVENT_OBJECT_SCHEMA columns are in fact always equal.
I chose to exclude the %CATALOG columns from the primary keys and relationship definitions. MySQL does not support catalogs, which is fine according to ISO 9075. However, as far as I can see, the MySQL implementation is not entirely consistent with ISO 9075. It's not a big thing though, considering the fact that catalogs are not supported. You can safely skip the next few paragraphs if you're not interested in features that are not, and most probably will not be supported (at least in the near future).
The CATALOG column is usually present as expected, that is, in those places where an object needs to be identified within a catalog (that is, if MySQL would support catalogs!). When a CATALOG column is present it always evaluates to the "NULL Value" because MySQL does not support catalogs, which is ISO 9075 compliant. There are some cases where one could expect a CATALOG column, but were it is ommitted without raising any questions: In COLLATIONS (COLLATION_CATALOG), CHARACTER_SETS (CHARACTER_SET_CATALOG), and in those places where a COLLATION or CHARACTER_SET could be referenced. Note that a fully compliant ISO 9075 implementation would have "NULL" CATALOG columns in these cases though (as well as a %_SCHEMA column!).
There are some other cases where the MySQL implementation omits CATALOG columns, and where it does raise questions. Consider the KEY_COLUMN_USAGE table. We can see a CONSTRAINT_CATALOG and TABLE_CATALOG column. The former would serve to reference (and thus identify) a table constraint (along with CONSTRAINT_SCHEMA and CONSTRAINT_NAME). The latter would serve to reference (and thus identify) a table column (along with TABLE_SCHEMA and TABLE_NAME and COLUMN_NAME).
So far, so good, but here we go: The KEY_COLUMN_USAGE table seems to be able to reference another table column via the REFERENCED_TABLE_SCHEMA, REFERENCED_TABLE_NAME and REFERENCED_COLUMN_NAME columns. This is used to define the mapping between a foreign key column and the corresponding primary key or unique constraint column. I would expect to see a REFERENCED_TABLE_CATALOG column for the sake of consistency. A total lack of CATALOG columns would do equally well in this respect.
But, okay. I'm done now. It's not really important, considering that the REFERENCED% columns are not even standard in KEY_COLUMN_USAGE. I feel that the current lack of support for the CATALOG concept justifies omitting these columns from the primary key definitions and relationships in the diagram. In fact, I feel that the omission improves the readability of the diagram.
The TABLE_CONSTRAINTS table lists all table constraints, that is, PRIMARY KEY, UNIQUE and FOREIGN KEY constraints. The columns that take part in the constraint can be found in the KEY_COLUMN_USAGE table. Therefore, it would make sense to relate these two tables, however, the diagram does not show such a relationship.
The reason for not having such a relationship in the diagram is that KEY_COLUMN_USAGE does not contain all columns to propertly relate the tables. Odd as it may seem, Table constraints in MySQL are *NOT* identified by a schema name and a constraint name. Even in one table, there can be two table constraints with the same name.
Interestingly, FOREIGN KEY constraints *ARE* required to have unique names in one schema, whereas UNIQUE constraints are only required to have unique names within one table. So, a particular table can have both a UNIQUE and a FOREIGN KEY constraint with an identical name. From the, it follows that the CONSTRAINT_TYPE column should be included in the primary key of TABLE_CONSTRAINTS. Because there is no such column in KEY_COLUMN_USAGE, the two tables cannot be related properly by joining over the common columns.
It is still possible to find out which rows form KEY_COLUMN_USAGE and TABLE_CONSTRAINTS correspond. When the common columns match, and the CONSTRAINT_TYPE equals 'UNIQUE', we should als require that the REFERENCED_TABLE_SCHEMA column in KEY_COLUMN_USAGE be NULL. When the CONSTRAINT_TYPE is 'FOREIGN KEY', we should require that the REFERENCED_TABLE_SCHEMA column in KEY_COLUMN_USAGE is not NULL. But as this kind of correspondence cannot be expressed in an ERD, ommitting the relationship altogether seems the only sensible thing to do.
Given the rules for unicity of constraint names, the omisson of the CONSTRAINT_TYPE in KEY_COLUMN_USAGE leads to other oddities. Because we need to look at the REFERENCED_% columns to know what constraint the column belongs too, I included these in the primary key definition. This leads to a paradox, as these column must then be not nullable. But Of course, they have to be nullable in case they're not foreign key columns. So either way, you have to compromise.